 Никто кроме инженеров поискового отдела Google не знает всех факторов ранжирования. Однако, если вы введёте запрос «200 факторов ранжирования», то получите несколько сотен результатов в выдаче. Первый раз Google объявил об использовании 200 факторов ранжирования 10 мая 2006 года, во Всемирный день свободы печати.
Никто кроме инженеров поискового отдела Google не знает всех факторов ранжирования. Однако, если вы введёте запрос «200 факторов ранжирования», то получите несколько сотен результатов в выдаче. Первый раз Google объявил об использовании 200 факторов ранжирования 10 мая 2006 года, во Всемирный день свободы печати.
Более подробно об этом вы можете прочитать в блоге самого Мэтта Каттса. Скорее всего, это число было выбрано, чтобы показать журналистам, насколько сложен алгоритм ранжирования Google. Если бы аудитория состояла из специалистов по информационным технологиям, то цифра была бы другая. Кроме того, в 2010 году Мэтт Каттс ещё раз упомянул, что Google учитывает более, чем 200 факторов ранжирования, каждый из которых, в свою очередь, имеет более 50 вариаций.
А теперь подумайте: вы уверены, что действительно знаете значение слов «ранжирование» и «индексация»? Многие начинающие или недостаточно опытные вебмастеры используют их как синонимы, хотя в действительности это два совершенно разных понятия и совершенно разные этапы работы поисковой системы.

Индексация ‒ это один из четырёх взаимосвязанных и взаимозависимых этапов в работе поисковой системы. Вот эти этапы:
1. Сбор данных.
2. Обработка.
3. Индексация.
4. Поиск.
Индексация ‒ это процесс обнаружения и отображения ресурсов во всей сети, которые связаны с искомой фразой или словом. Эту работу поисковая система выполняет самостоятельно, хотя вебмастера и могут ей помочь путём оптимизации своих сайтов. Таким образом, с помощью индексации поисковик решает, на каких ресурсах находится ответ на запрос пользователя, но не в каком порядке их размещать в выдаче. Это происходит на следующем этапе. На втором этапе учитываются все нюансы, включая историю поиска и тип устройства, с которого пришёл поисковый запрос. Но самую главную роль здесь играет контекст.
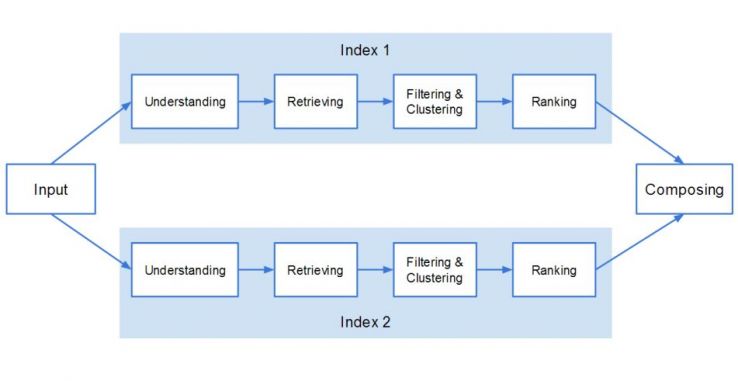
Третий этап включает в себя 4 шага:
1. Понимание поискового запроса. Поисковый алгоритм «Колибри» как раз и разработан, чтобы лучше понимать контекст поисковых запросов пользователей, уделяя больше внимания вкладываемому в поисковый запрос смыслу, а не ориентируясь исключительно на ключевые слова.
2. Выборку документов из индекса с учётом тэга.
3. Фильтрацию и группировку. После того, как Google проанализирует запрос и отберёт подходящие источники, в дело вступает фильтр «Панда» и другие спам-фильтры.
4. Ранжирование. Именно на этом этапе Google использует энное число факторов ранжирования, но не раньше.
Не стоит забывать, что содержание и вид поисковой выдачи во многом ещё зависит и от устройства, с которого был сделан поисковой запрос.
Почему в среде вебмастеров так устойчивы мифы вроде «200 факторов ранжирования»? Потому что они воспринимаются не столько как источник информации, сколько в качестве панацеи, выполнив все предписания которой, можно уверенно подняться в выдаче и занять её верхние строчки. Возьмём для примера вот этот список и начнём с самого простого.
1. Плотность ключевых слов (фактор ранжирования №7).
Сердце кровью обливается, когда я читаю: «…хотя этот фактор уже не так важен как прежде, Google все ещё использует плотность ключевых слов для определения релевантности страницы…» Плотность ключевых никогда не была фактором ранжирования. Ноги этого мифа растут из трудов Стивена Робертсона и Карена Джонсона 70-80 годов, в которых, в частности, они разработали формулу ранжирования, известную как «Okapi BM25». Может, оно и было актуально тогда, но сейчас на дворе 2014 год. Ключевые слова используются, чтобы сайт попал в поле зрения поисковика. Но и только. Нередки случаи, когда страница ранжируется по запросу, ключевых слов на который страница даже и не содержала, но Google посчитал остальной контекст достаточно подходящим.
2. Скрытое семантическое индексирование (факторы ранжирования №18/19).
Скрытое семантическое индексирование было разработано и запатентовано в 1990 году, ещё до появления Интернета. Целью его создания была индексация небольших (содержащих менее 10 000 документов) баз данных. На основе скрытого индексирования был разработан инструмент для генерации ключевых слов, который как обещалось, умел бы находить синонимы и близкие по смыслу слова. Совершенно ясно, что для Интернета подобный метод не подходит, поскольку база данных того же Google гораздо более объёмна, да к тому же слишком часто меняется.
3. YouTube (фактор ранжирования №76).
Нет сомнений, что в своей выдаче Google отдаёт предпочтения видео с YouTube. Каким боком это повернуть к факторам ранжирования? Здесь налицо манипуляция выдачей с целью вывести в топ свои сервисы, но это никак не фактор ранжирования.
Классический пример того, как наукообразные факты оказываются недостоверными и даже опасными.
4. Доступность сайта (фактор ранжирования №69).
Если ваш сайт часто бывает недоступен и постоянно выдаёт Error 500, он будет понижен в выдаче. Абсолютно верно. Однако, здесь речь об индексации, а не о ранжировании. Помните, что было сказано выше о важности правильного понимания терминов?
5. Ключевое слово в домене (фактор ранжирования №3).
Этот «фактор» попал в список, поскольку в 2011 году ряд вебмастеров (и я в том числе) заметили, что EMD и PMD имели явное преимущество в ранжировании. Но уже в 2013 году при проведении такого же исследования, результаты оказались не столь убедительными. Следует иметь ввиду, что это всего лишь субъективное мнение, основанное на личном опыте, но никак на фактор ранжирования.
6. TLD определённой страны (фактор ранжирования №10).
Действительно, домены верхнего уровня имеют более сильный геотаргетинг, чем сайты в поддоменах или папках. Однако ни один SEO-специалист в мире не будет утверждать, что домен верхнего уровня всегда ранжируется лучше, чем сайт с именем домена более низкого уровня. Неправда и то, что сайты, расположенные на домах .es или .it не могут хорошо ранжироваться за пределами Google.es или Google.it. В одной из своих прошлых статей я приводил пример, когда сайты с латиноамериканскими TLD ранжировались выше, чем сайты с доменным именем .es в Google.es. Такое часто бывает в региональных версиях Google. Этот пункт наглядно демонстрирует то, как банальное незнание может привести к опасному заблуждению.
7. Использование Google Analytics и Google Webmaster Tools (фактор ранжирования №78).
Цитирую: «Некоторые уверены, что использование этих двух инструментов способствует ускорению индексации и непосредственно влияет на позиции в выдаче». «Некоторые уверены»?! Кто такие эти «некоторые»? Студенты, тусующиеся на форуме? Специалисты по информационным технологиям? Ну кто, кто же? Всё это не более чем домыслы.
8. Гостевые посты (фактор ранжирования №91).
Ссылку (или несколько ссылок) из гостевого поста могут посчитать попыткой манипулировать выдачей и будут рассматривать как спам с последующим понижением в выдаче. Опять же, речь идёт о применении спам-фильтра и соответственно третьей стадии поиска, а не о ранжировании.
9. Лайки и число репостов на Фейсбуке (фактор ранжирования №157/158).
Google не видит лайки и не знает, сколько людей нажало на кнопку «Поделиться». Поэтому они не могут быть фактором ранжирования. И точка. Это подтверждается словами Мэтта Каттса: «Мы за единые стандарты в открытом Интернет-пространстве. Мы не хотим зависеть от компаний, вроде Фейсбук или Твиттер, чьи данные нам недоступны для сканирования». Между социальными сигналами и позицией в выдаче действительно есть связь, но эта связь не является причинно-следственной. Здесь скорее всего ступают в силу поведенческие факторы, которые опосредованным образом влияют на ранжирование.
10. Сотрудники в LinkedIn (фактор ранжирования №171).
Это заблуждение основано на статье Рэнда Фишкина, написанной в 2011 году. Но только в этой статье речь шла совсем о другом. Рэнд там высказал предположение (абсолютно верное), что в будущем Google начнёт учитывать «брендовые» сигналы. Но там ни слова не было о том, что Google собирается учитывать регистрацию сотрудников на LinkedIn.
Все ли списки факторов ранжирования плохие? Нет, но вместо изучения голой теории лучше создать сайт и проверить на практике, какие из советов работают, а какие нет, а также на собственном опыте понять принципы работы поисковой системы.
